联系电话:020-88888888
联系电话:020-88888888
fmincon 里有四种算法:
Trust region reflective(信赖域反射算法)
Active set (有效集算法)
Interior point (内点算法)
SQP (序列二次规划算法)
序列二次规划的算法百度文库就有,自己敲一下就好了
是因为效率的问题,line search一类的方法必须在每轮跌代都计算完整的函数值,这在传统的优化问题中一般是OK的,但深度学习这样的问题中计算量太大。
实际上,优化中也有一些不用计算函数值的方法来选取步长,例如Barzilai-Borwein method,但这个方法在深度学习这类非凸问题中并不适用。
其实归根结底,还是因为优化和深度学习这两个圈子的文化氛围造成的。做优化的大部分都是数学出生,Adam这类heuristic的方法在他们眼中毫无价值,他们认为好的方法一定是要有理论上的解释和证明的(Adam paper中虽然有证明,但只能说明这个算法是收敛的,理论上看起来并没有任何优势)。而对于做深度学习的人来说,方法跑的快那就足够了。
泻药 @又红又正
我提供一种思路来求解globally optimal solution,并讨论一下复杂度问题。
需要三个引理。第一个引理: 对于 ,有
。 第二个引理是Max-min inequality,第三个引理是Minimax theorem。
以求解(2)为例,根据齐次性,可以不失一般性地令 。将第一个引理代入(2),得到
其中 表示
。从(A)到(B)时交换max-min顺序,使用了max-min inequality。
我们只需要讨论在什么条件下inequality取等号。为此,我们从Semi-Definite Relaxation ( SDR)的角度来得到上述关系
从(SDR1)到(SDR2)时交换max-min顺序,使用了minimax theorem。如果仔细检查的话,会发现minimax theorem的一个条件是求min的变量的约束域是紧凸集合。这个条件在这个问题不是完美满足,但是很显然这里最优的 的每一个分量都不可能是0,也不可能是无穷,所以可以人为地选择一个充分小的正数
和充分大的
将约束域改为
而不改变原问题的最优解,从而应用minimax theorem。
很显然,当且仅当(SDR1)的外层max问题有rank-one solution时,inequality取等号。根据min-max问题的saddle point solution关系[1],(SDR1)的外层max问题的解集是(SDR2)的内层max问题的的解集的子集。因此,inequality取等号的一个充分条件是在(C)的最优解 处,矩阵
有简单的最大特征值(几何重数为1)。注意到(C)关于
是严格凸的,因此最优的
是唯一的,所以在解完(C)后做后验分析(posterior analysis)会非常方便。当矩阵
有多重最大特征值时,PCA或者Gaussian Randomization就可以使用了,此时的performance guarantee分析是另一个研究问题了。当然SDR可以直接用在(1)或者(2)上,相当于是primal form,而我提供的是dual form。dual form的好处是,做后验分析方便,求解复杂度更低,甚至我们可以先验地分析出在一些条件下SDR只有rank-one solution。
由于(2)的目标函数和约束函数都是齐次的强制函数(Coercive function),还可以得到与(2)等价的一个问题形式是 。这种形式是一个凸体(半范数球)上的norm-maximization问题,通常都是NP-hard[2][3]。这种形式也给出了一种基于rounding求approximate solution的思路,即将这个凸体替换为它的内接椭球,比如体积最大的内接椭球或者体积最大的Dikin椭球(Dikin ellipsoid with volumetric center)[4][5],此时问题变为一个信赖域子问题,虽然非凸但可以全局求解,并且可以根据rounding ratio给出performance guarantee。
[1]Hiriart-Urruty J B, Lemaréchal C. Convex analysis and minimization algorithms[M]. Springer-Verlag, 1993.
[2]Bodlaender H L, Gritzmann P, Klee V, et al. Computational complexity of norm-maximization[J]. Combinatorica, 1990, 10(2):203-225.
[3]Knauer C, K?nig S, Werner D. Fixed-Parameter Complexity and Approximability of Norm Maximization[J]. Discrete & Computational Geometry, 2015, 53(2):276-295.
[4]Jarre F. Optimal ellipsoidal approximations around the Analytic center[J]. Applied Mathematics & Optimization, 1994, 30(1):15-19.
[5]Barrett M, Walsham G, Doyle J R, et al. Ellipsoidal Approximations of Convex Sets Based on the Volumetric Barrier[J]. Mathematics of Operations Research, 1999, 24(1):193-203.e
牛顿法的本质就是:就是在当前点,把原函数近似看做二次函数,然后把这个二次函数的最小值点,设为下一次迭代的起点。
其他方法如下:
首先可以通过麦克劳林公式进行逼近, 函数的麦克劳林公式如下:
然后代码化即可:
def factorial(n):
if n == 0:
return 1
return n * factorial(n-1)
def sin(x, m):
value = 0
for i in range(1, m+1):
value += ((-1) ** (i - 1)) * ((x ** (2*i-1)) / factorial(2*i-1))
return value为了验证数值逼近是否准确,使用numpy模块进行对比
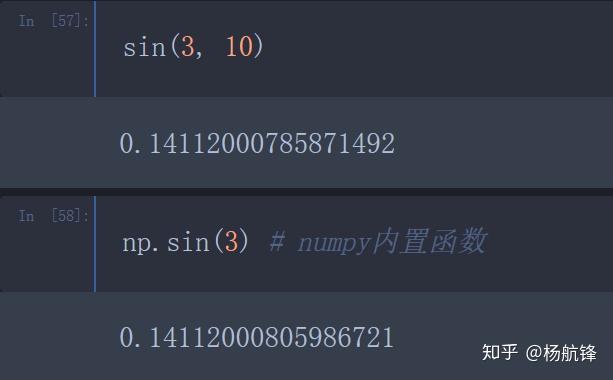
当然可以啦,在不知道解析式的情况下,可以使用数值微分(Numerical Differentiation)计算梯度。原理也非常简单,反正梯度的含义就是自变量变化一点点,函数值对应的变化情况,那么在计算机中,只要对自变量进行一个轻微的扰动,和原始函数值相减,就可以算出来梯度了。
比如著名的Python科学计算框架Scipy就是采用的数值微分,例如,基于Scipy,我们可以轻松地用BFGS算法优化一个不可导函数。
import numpy as np
from scipy.optimize import minimize
def func(x):
print(x)
return np.sum(np.absolute(x - 5))
result = minimize(func, np.zeros(5), method='BFGS')
print(result)阅读Scipy源码的话,就可以发现Scipy采用的是一个与"np.finfo(float).eps"相关的扰动量,因此无需要写出解析表达式,就可以得到梯度信息。
可以的
题主提到了有几十维变量算是高维问题了,用进化算法对算力要求较大
数学优化中有一个分支叫做无导数优化(有很多别名:DFO,无梯度优化,零次优化,gradient-free,derivative-free等)
大多数优化方法都需要利用目标函数或者约束的一阶信息,也就是梯度或者次梯度。实际问题里面的一阶信息往往不能有效计算,这种都算作是黑盒问题。黑箱系统是无法获取梯度的,也就是无导数优化可以上场的时候。最近无梯度算法比较火的应用之一是对深度神经网络黑箱系统的攻击:
Chen P Y, Zhang H, Sharma Y, et al. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models[C]//Proceedings of the 10th ACM workshop on artificial intelligence and security. 2017: 15-26.
下面是基于DFO的若干经典方法,分为基于搜索和基于模型两类:
近年来还有一些随机化算法、分解与并行算法
扯远了,回到题主的问题,BFGS方法是一种类牛顿法,其使用大致有几种
Derivative-free optimization of noisy functions via quasi-Newton methods, Albert S. Berahas, Richard H. Byrd, Jorge Nocedal, SIAM Journal on Optimization, 2019.
A derivative-free Gauss–Newton method, Coralia Cartis, Lindon Roberts, Mathematical Programming Computation, 2019.
数学优化中的无梯度方法是个宝藏
都看到这儿了,点个赞吧
推荐题主自己学下正则化的东西再来求解析解吧,这里直接给结果了。

Newton-CG啊,其实挺简单的。传统的牛顿法是每一次迭代都要求Hessian矩阵的逆,这个复杂度就很高,为了避免求矩阵的逆,Newton-CG就用CG共轭梯度法来求解线性方程组,从而避免了求矩阵逆。
就是个这。
在最近的传感器校准算法学习中,有一些非线性的代价函数求解使用最小二乘法很难求解,使用LM算法求解会简单许多,因此学习了一下LM算法的基础记录一下。
LM 优化迭代算法时一种非线性优化算法,可以看作是梯度下降与高斯牛顿法的结合,综合了两者的优点。
对于一个最小二乘的问题,如下:
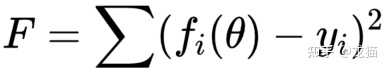
其中 y(i) 为第 i 组数据的真实值或理论真实值,fi(θ) 为第 i 组数据的预测值,目的就是找到一组 θ,使得代价函数达到最小值。通常,需要指定一个初始 θ0,不断优化迭代,产生 θ1,θ2 ,最终收敛到最优值 θ。
在收敛的过程中,需要两个参数,收敛方向与收敛步长:
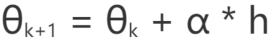
h 为收敛方向
α 为收敛步长
在后续 LM 的迭代计算中,需要用到雅可比矩阵,雅可比矩阵的简易理解过程如下:
在 n 维空间中的向量,假设 x 与 y 的映射关系为 y:
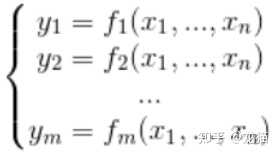
以上的映射关系用 F 表示。
那么雅可比矩阵就可以写作:
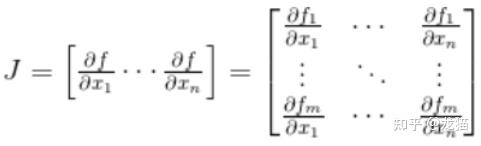
雅可比矩阵的意义就在于,假设 p 是向量中的一个点,F 在点 p 处是可微的,那么雅可比矩阵 J(p) 就是这点的导数,定义一个 x,当 x 足够接近 p 时,就可以得到:
F(x) ≈ F(p) + J(p) * (x - p)
F(x) - F(p) ≈ J(p) * (x - p)
即:
Δy ≈ J(p) * Δx
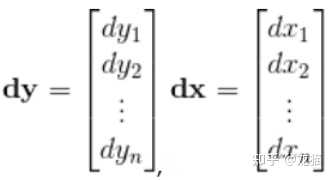
转化为微分:
dy=J(p) dx
将上述的微分与雅可比矩阵展开:
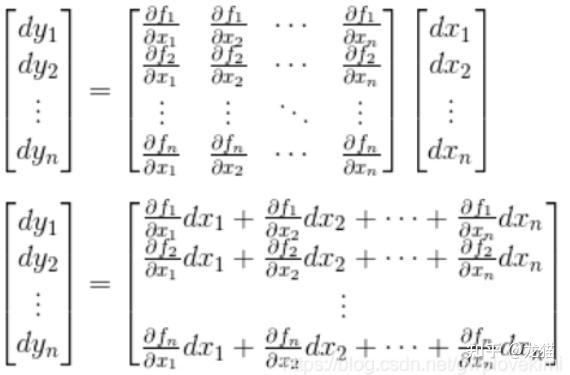
LM 代价函数,对 θ 求偏导,就是一个雅可比矩阵,雅可比矩阵的更新在 LM 算法中,非常关键。
LM算法的迭代可以理解为结合了梯度下降与高斯牛顿的优点,因此其迭代公式可以对比观察。
梯度下降

dot(J) 就是 J 的一阶倒数
高斯牛顿
高斯牛顿在牛顿迭代的基础上,使用了雅可比矩阵的平方,使得求解更快,但如果初始值不在最优解附近,则求解就可能出错:


f 表示代价函数中的残差,J 表示雅可比矩阵
LM算法
由于 J_T*J 在某些情况下是不可逆的,因此 LM 增加了一个系数 λ*I (I 为单位矩阵) ,以此来保证等式左边是一定可逆的,就可以求解所有的情况:


1)当 λ 设置的比较大时,就相当于是梯度下降,适合当前的估计参数距离最优解比较远的情况
2)当 λ 设置的比较小时,就相当于高斯牛顿,适合估计参数距离最优解比较近的情况
因此在 LM 算法中,需要根据情况来调整 λ 的值来得到最优解
通常遵循以下步骤:
1.采样n组数据,定义代价函数,如下所示:
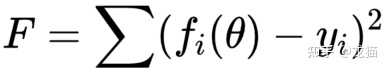
fi 表示模型对第 i 个样本的预测值, y 表示真实值或者理论真实值。
2.初始化参数向量,需要初始化模型的估计参数 θ,可以随机初始化或根据经验设置初值
3.计算雅可比矩阵,即代价函数关于估计参数向量 θ 的雅可比矩阵:
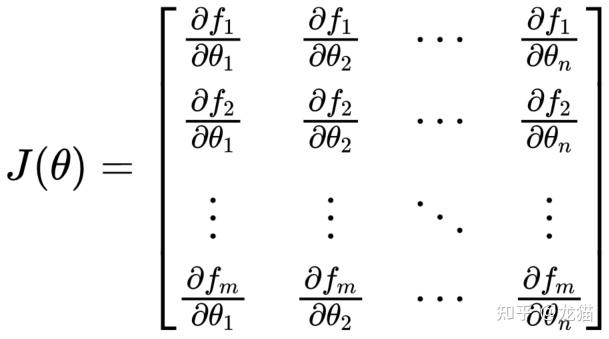
4.计算初始代价函数值,将初始估计参数 θ 带入
5.设置 LM 算法的参数,包括初始阻尼因子 λ ,最大迭代次数,迭代精度,收敛步长等
6.迭代更新参数向量,雅可比矩阵(有一些简单的情况雅可比矩阵只与采样值有关,就可以只计算一次),这里将收敛补偿设置为1,即α=1

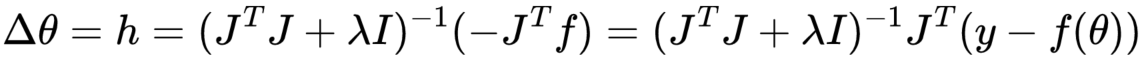
之后更新新的估计参数:
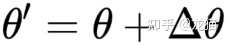
并使用新的估计参数带入代价函数 F,计算新的代价函数是否更小,如果更小则接受更新,否则,拒绝更新,并增大 λ:
λ=10 * λ
如果新的参数更优,则将 λ 减小:
λ=0.1 * λ
7.更改估计参数之后,再次使用 n 组采样数据,重复 6 步骤,如果代价函数值变化小于设定的迭代精度,或达到最大迭代次数,则停止迭代,返回跌代后的参数向量 θ
假设需要拟合一个二次多项式 f=a * x^2 + b * x + c,假设真实的多项式参数 a=2,b=-3,c=-1,之后添加随机噪声。
按照 LM 算法的步骤,定义初始的参数估计矩阵为:
theta=[1,1,1]
收敛步长 alpha 定义为1,不变
迭代次数为 1000 次,采样 100 组 x,y 数据。
之后按照这个简化步骤,就可以迭代计算出多项式的值:
1)更新雅可比矩阵
2)计算迭代步长 h
3)判断是否更新估计参数(根据新的代价值是否变得更小),如果要更新,则将迭代步长加到上一次的估计参数矩阵 theta 中,并减小 lambda ;反之,则拒绝更新,并加大 lambda
(lambda 越小,越适合接近最优解的时候,lambda越大,越适合距离最优解较远的时候)
针对此例子,雅可比的通式为:
其中,n 表示估计参数矩阵的维度,m 表示采样次数,f 表示代价函数中的预测方程:
计算之后,此多项式的雅可比矩阵为:

只是恰好这个例子的雅可比矩阵偏导求解出来是不包含代预估变量的,可以只更新一次,正常是每次迭代都需要更新的。
最终的拟合效果如下:
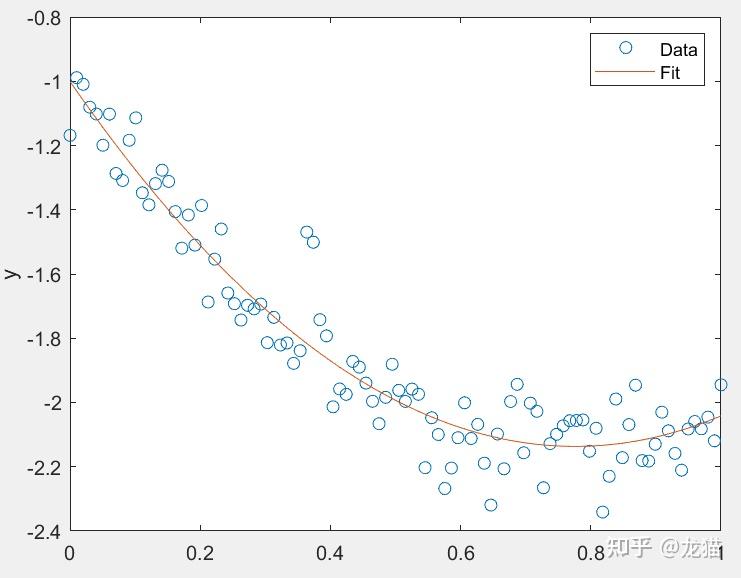
拟合出的估计参数与实际值也是接近的

编者按
本文旨在给出Nesterov加速算法之所以能对常规一阶算法加速的一种代数解释,这种观点来自于将此种方法看成gradient descent(primal view)和mirror descent(dual view)的线性耦合(linear coupling)。我们知道,一阶算法常用于深度学习中对神经网络损失函数的训练当中,而本文则是给出了Nesterov加速算法背后的一些更深层次的原理性探讨。
我们知道,著名的Nesterov加速算法由Nesterov在83年即提出,并证明了广泛情形下这种一阶算法(即只用到gradient信息)在凸优化问题中的收敛速度达到最优(match information lower bound)。然而,这么多年以来,为何形式上一个简单变化(比如,基于gradient descent)之后的算法就能将gradient descent的收敛速度整整提升一个量级,达到最优,这背后隐含的原理一直是很多人难以理解和解释的。我记得之前在Prof Robert Freund课上他讲Nemirovski回忆第一次见到Nesterov这个work的时候,“I was very surprised that a seemingly mere algebraic trick can make a real difference in the algorithm in terms of its convergence behavior”... "It was a beautifully written proof that I felt like I didn't understand what's behind."
文章声明
作者:覃含章
责任编辑:覃含章
微信编辑:玖蓁
知乎编辑:乐陶
文章由『运筹OR帷幄』获得授权原创发布,如需转载文章请在公众号后台获取转载须知
本文旨在给出Nesterov加速算法之所以能对常规一阶算法加速的一种代数解释,这种观点来自于将此种方法intepret成gradient descent(primal view)和mirror descent(dual view)的线性耦合(linear coupling)。这种观点是由朱泽园和Lorenzo Orecchia在14年提出([1])。
自然,这并不是唯一一种intepret为何这种方法可以加速一般一阶算法的观点。比如,Nesterov最早基于potential function的proof:[2]基于微分方程的interpretation(看成离散化的ODE):[3]基于椭圆法(ellipsoid method)的几何加速算法(形式上已经和Nestrov的原始方法区别很大了):[4]
其实这些其它的观点也很有意思,不过和本文的观点出发点完全不同,所以本篇文章不会涉及。
1.一些关于Gradient Descent和Mirror Descent的基本观点
本节我们给出一些high level的对于gradient descent(GD)和mirror descent(MD)的相关讨论。

我们指出,GD在primal view下的本质是利用convexity minimize一个quadratic upper bound(同样,这点在专栏文章里已经有详细讨论)。具体来说,固定步长 的gradient descent的更新步骤可以写成:
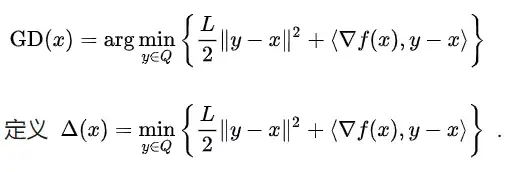


注意这里我们MD的收敛速度比GD要慢一个量级,因为我们考虑了非光滑情形,即每一步MD甚至不一定会降低目标函数值。至于光滑情形下的分析和GD类似,具有同样速度的收敛速度,详情请见公众号之前的文章。
同样我们指出一个很显然的观察, MD与GD相反,在(sub)gradient比较小的时候更加有效,这是因为核心引理里的regret实际上在这种情况才比较小,反之可能会很大。
2.基于线性耦合的加速



参考文献:
[1]Allen-Zhu, Zeyuan, and Lorenzo Orecchia. "Linear coupling: An ultimate unification of gradient and mirror descent." arXiv preprint arXiv:1407.1537 (2014).
[2]Nesterov, Yurii. "A method of solving a convex programming problem with convergence rate O (1/k2)." Soviet Mathematics Doklady. Vol. 27. No. 2. 1983.
[3]Shi, Bin, et al. "Understanding the acceleration phenomenon via high-resolution differential equations." arXiv preprint arXiv:1810.08907 (2018).
[4]Bubeck S, Lee YT, Singh M. A geometric alternative to Nesterov's accelerated gradient descent. arXiv preprint arXiv:1506.08187. 2015 Jun 26.
-------相关文章推荐------
下文为介绍mirror descent方法的综述教程,强烈推荐对这方面基础知识不熟悉的同学在阅读本文前先行阅读。
点击蓝字标题,即可阅读《【学界】Mirror descent: 统一框架下的一阶算法》
其他
作者 | 袁淦钊
单位 | 鹏城实验室
研究方向 | 数值优化、机器学习
这次向大家分享的工作是鹏城实验室牵头,联合腾讯AI实验室和中山大学在SIGKDD 2020上发表的文章:A Block Decomposition Algorithm for Sparse Optimization。

论文标题:A Block Decomposition Algorithm for Sparse Optimization
论文链接:https://arxiv.org/pdf/1905.11031.pdf
相关资料(代码/PPT/相关论文):https://yuangzh.github.io
稀疏优化由于其内在的组合结构,一般比较难求解。组合搜索方法可以获得其全局最优解,但往往局限于小规模的优化问题;坐标下降方法速度快,但往往陷入于一个较差的局部次优解中。
我们提出一种结合组合搜索和坐标下降的块K分解算法。具体地说,我们考虑随机策略或/和贪婪策略,选择K个坐标作为工作集,然后基于原始目标函数对工作集坐标进行全局组合搜索。我们对块K分解算法进行了最优性分析,我们证明了我们的方法比现有的方法找到更强的稳定点。此外,我们还对算法进行了收敛性分析,并构建其收敛速度。大量的实验表明,我们的方法目前取得的性能臻于艺境。我们的块K分解算法的工作发表在国际人工智能会议SIGKDD 2020和CVPR 2019上。
本文主要讨论求解以下稀疏约束或稀疏正则优化问题:
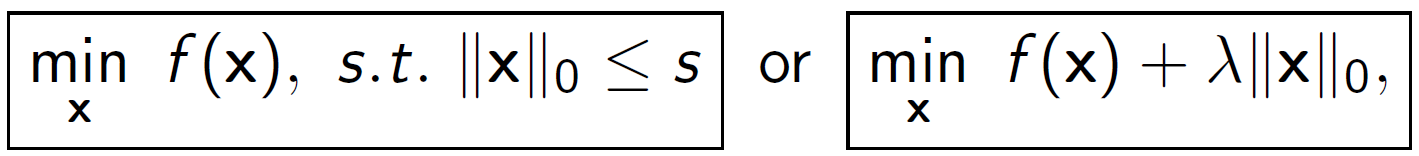
我们假设f(x)是光滑的凸函数。这类问题在压缩感知、信号处理、统计学习等问题上有着广泛的应用。
以下是我们提出的块K分解算法:

算法非常简洁,只有两步。第一步:选择K个坐标集,第二步:基于原始目标函数f(x),对选择的K个坐标作全局组合搜索。
该算法也被称为块坐标下降方法,但和以往方法有所不同,有以下四点值得注意:
目前常见的稀疏优化方法有四类:
a. 第一类是松弛近似方法。这类方法最大的缺点是不能直接每一步控制问题的稀疏特性。
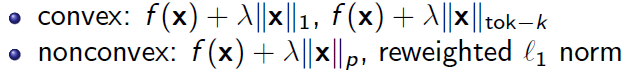
我们方法优点:可以直接控制解的稀疏特性。
b. 第二类是贪心算法。这类方法最大的缺点是初始化点必须为空集或零。
我们方法优点:可以任意初始化,而且最终精度对初始化不敏感。
c. 第三类方法是全局优化算法。这类方法的最大缺点是仅限于小规模问题。
我们方法优点:利用了全局最优化算法,提高了算法精度。
d. 第四类方法是临近梯度方法。这类方法的最大缺点是算法陷入到较差的局部次优值。
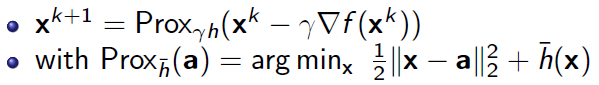
我们方法优点:从理论和实验上都优胜于临近梯度方法。
以下我们定义稀疏优化问题的稳定点:基本稳定点、李普希茨稳定点,块K稳定点。

基本稳定点就是指,当非零元指标集已知时,解达到全局最优。这类稳定点的一个很好的性质是:稳定点是可枚举的,这使得我们能够验证某个解是否是该问题的全局最优解。
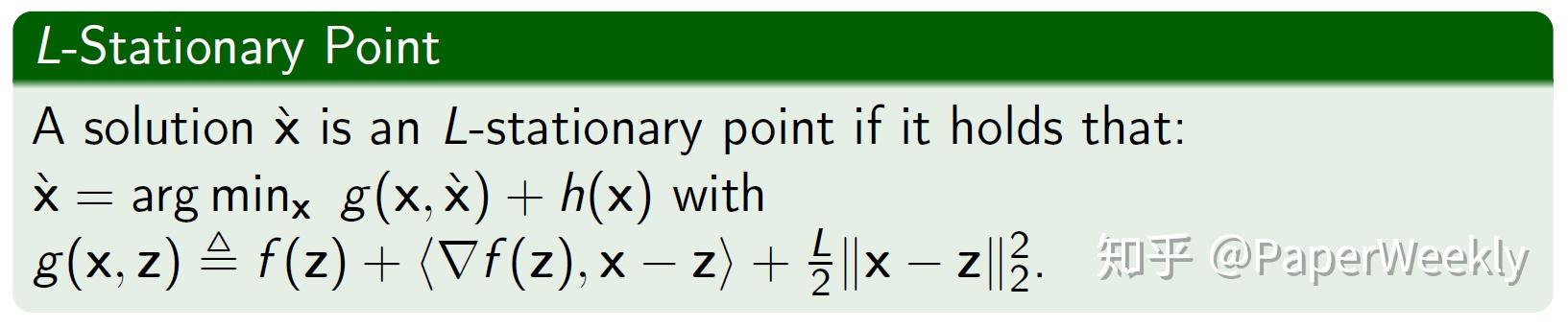
李普希茨稳定点是通过一个临近算子来刻画,经典的临近梯度法得到的是李普希茨稳定点。临近梯度法每一步需要求解一个临近算子,该算子有快速封闭解,但是这种简单的上界替代函数方法通常导致算法精度不高。

这是我们提出的块K稳定点的概念。块K稳定点是指,当我们(全局地)最小化任意的K个坐标(其余的n-K个坐标固定不变),我们都不能使得目标函数值得到改进。
我们得到以下的关于这三类稳定点的层次关系:
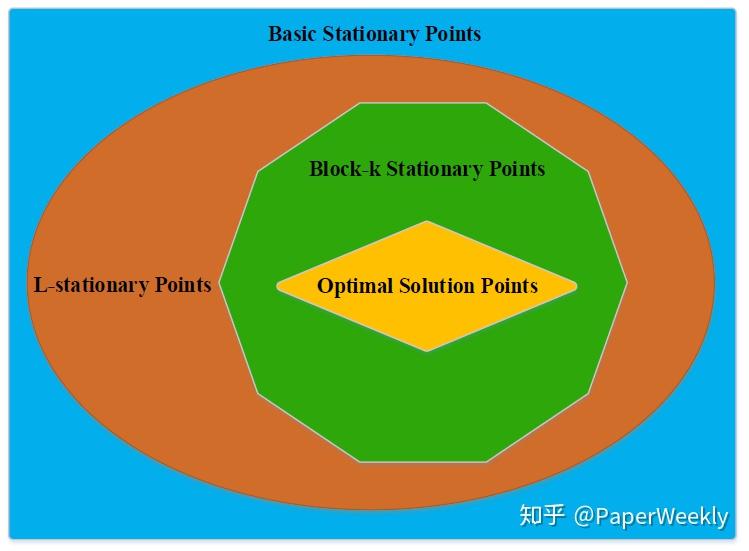
我们已证明,我们的块K稳定点比以往的基本稳定点和李普希茨稳定点更强。可以以上图举例。假如我们从上方的图中的绿色区域(块K稳定点)选择一个点,该点落入黄色区域(最优点集)中有一个概率P1;我们从上方的图中的红色区域(李普希茨稳定点)选择一个点,该点落入黄色区域(最优点集)中有一个概率P2。由于P1总是大于P2,因此我们的方法更大的概率落入最优解集中。
稀疏优化问题由于其组合结构,完全求解这个问题属于大海捞针。我们对稀疏优化问题的全局最优点有了更准确细致的描述,我们对这类问题给出了更精确的近似。
可以打个比喻:甲说,鹏城实验室在广东;乙说,鹏城实验室在广东深圳;丙说,鹏城实验室在广东深圳南山区万科云城(详细广告信息可参考本文下方)。丙的说法更准确。
我们证明了算法在期望意义上收敛到块K稳定点。

此外,我们证明了算法线性收敛性质(我想大家可能不太感兴趣,可参考我的论文和PPT)。
6.1 对于稀疏约束优化问题,我们比较了以下9种方法:
实验1

结论1
实验2
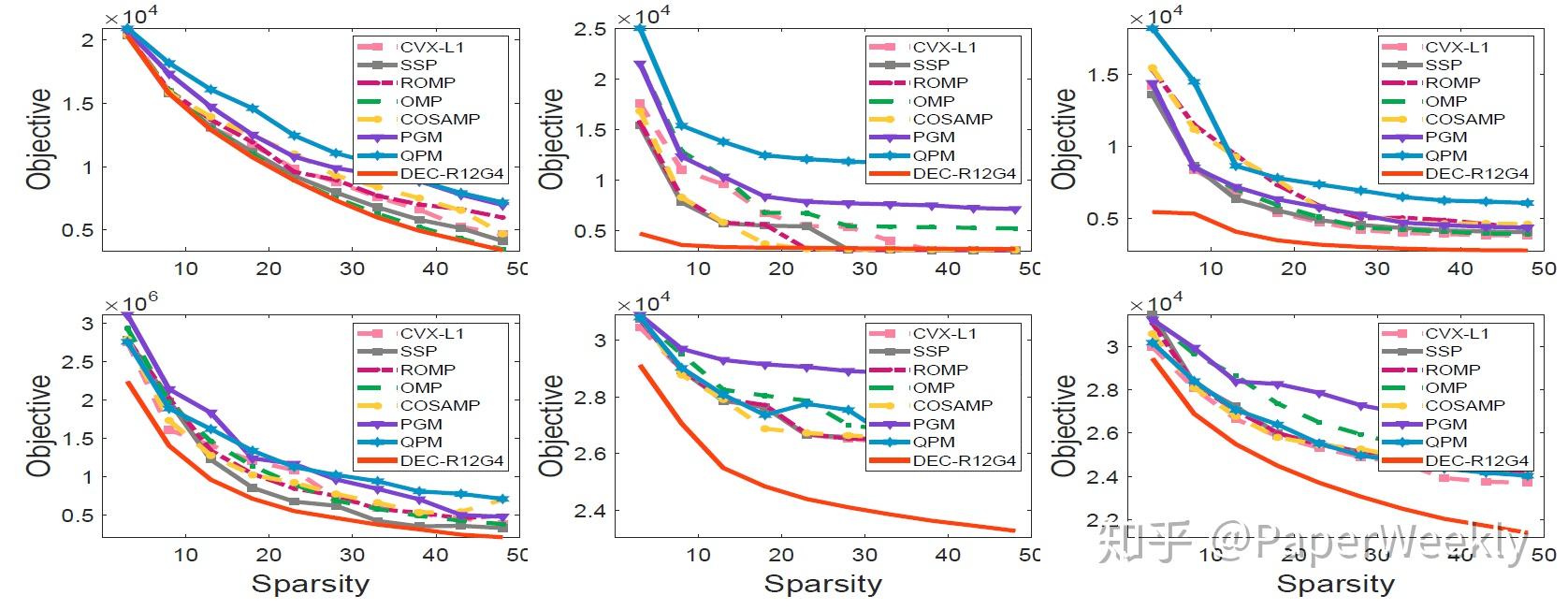
结论2
6.2 对于稀疏正则优化问题,我们比较了以下5种算法:
实验1
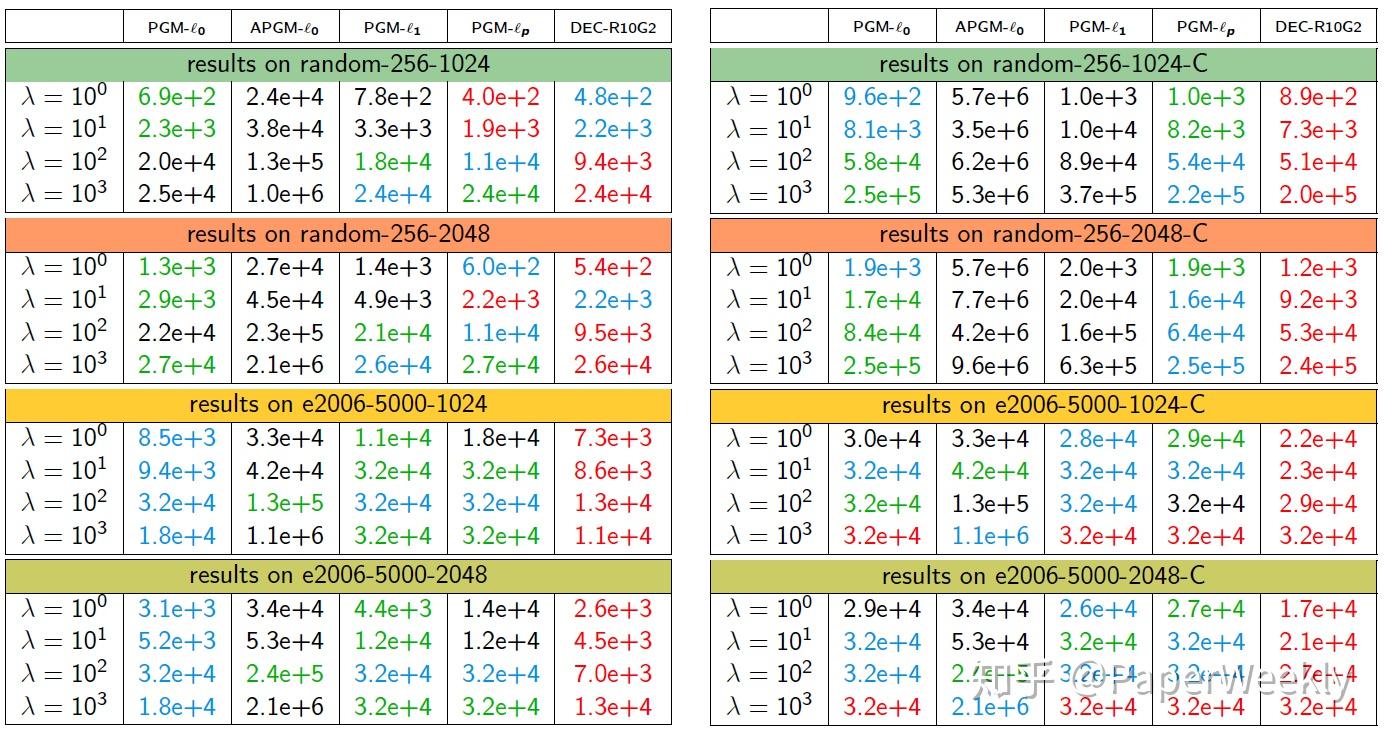
结论1
我们提出了一种求解稀疏优化问题的有效实用的方法。我们的方法利用了组合搜索和坐标下降的优点。我们的算法无论从理论上还是从实际上,都优于目前最具代表性的稀疏优化方法。我们的块分解算法已被扩展到解决稀疏广义特征值问题(见CVPR 2019)和二值优化问题。
岗位名称:博士后/助理研究员
工作地点:鹏城实验室(深圳南山区万科云城)
研究方向:数值算法/(半)离散优化/二阶优化/非凸优化/非光滑优化/机器学习
应聘材料:个人简历+学术成果(论文、科研项目、所获奖项等)发送到下方邮箱
应聘条件:35岁以下近三年内取得计算机/计算数学等学科博士学位+在数值优化/机器学习/机器视觉/数据挖掘等领域以第一作者发表过高水平论文(e.g., CCF A类/SIAM Journal)
岗位待遇:全球范围内有竞争力
联系方式:yuangzh@pcl.ac.cn
#投 稿 通 道#
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
来稿标准:
? 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
? 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
? PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
投稿方式:
? 方法一:在PaperWeekly知乎专栏页面点击“投稿”,即可递交文章
? 方法二:发送邮件至:hr@paperweekly.site ,所有文章配图,请单独在附件中发送
? 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
加入社区:http://paperweek.ly
微信公众号:PaperWeekly
新浪微博:@PaperWeekly
这篇文章中,我们讨论函数梯度的Lipschitz属性对保证数值算法收敛的重要性。
在数值优化算法中,函数梯度的Lipschitz属性是一个非常重要的性质。如果我们需要优化的函数的梯度具有Lipschitz属性,我们常常能保证数值算法的收敛性,并且能使用加速算法,使得数值算法有更快的收敛率。本文的内容来自于论文《Fast Alternating Direction Optimization Methods》,我们从Lipschitz属性的角度来介绍这篇文章的部分内容。下面,我们首先介绍一下Lipschitz属性的概念。然后,我们介绍几个数值算法的收敛性是如何依赖于Lipschitz条件的。
对于一个函数,我们记其梯度为
。如果存在一个正实数
,使得
满足
那么,我们称是Lipschitz连续的,我们称
为
的梯度的Lipschitz常数。因为
在点
处沿着
方向的导数可以被定义为
因此,我们结合与
可以看出,
为Lipschitz连续保证了
图像是连续的,并且没有十分陡峭的地方,即函数
的二阶导数是有限的。例如,下列函数的梯度满足Lipschitz连续:
而下面的函数的梯度不满足Lipschitz连续:
接下来,我们看函数梯度的Lipschitz属性如何保证了各种算法的收敛性。我们假设之后所涉及的函数都是凸函数。
这里,我们考虑单个函数的优化。具体地,我们想要解决下列优化问题:
我们在之前的文章中(《常微分方程与优化算法》,《从变分法的角度看Nesterov加速算法》,《总结优化算法收敛性证明的两类方法》,《海森黎曼梯度流求解带限制凸优化问题》),多次提到梯度下降,并且在《总结优化算法收敛性证明的两类方法》中,总结了证明算法收敛性的两种方法。这里我们给出在Lipschitz条件下梯度下降的收敛性。使用梯度下降,我们有下列迭代算法:
其中,为第
步的迭代结果,而
为每一步的步长。可以证明,当
,算法收敛。
梯度下降算法具有一阶的收敛性。一般地,想要有高阶的收敛性,我们需要目标函数更高阶的导数。Nesterov注意到,仅使用梯度,也能得到二阶的收敛性。具体地,为了解决问题,我们设置
随后,我们有下列的迭代算法:
可以证明,当时,算法
具有二阶收敛性。
这里,我们考虑的情况,具体地,我们考虑下列优化:
我们仍然可以使用梯度下降来计算,但是在一般情况下两个函数之和的梯度的Lipschitz常数大于单个函数的Lipschitz常数。因此,对类似
的问题直接使用梯度下降,我们可能需要更小的步长,使得需要更长的收敛时间。另外,如果
中,函数
和
中其中一个函数不可求导数,那么我们便无法使用梯度下降。我们需要其他办法。下面,我们讨论算子划分的算法,看算子划分算法的收敛性与Lipschitz条件的关系。
向前向后算子划分算法算法使用下面的迭代更新
可以证明,当(
为
的梯度的Lipschitz常数)时,算法
收敛。
利用Nesterov加速的思想,FISTA算法提供了Forward-Backward Splitting的一个加速版本。具体地,FISTA算法使用下面的更新:
其中,,
。可以证明,当
(
为
的Lipschitz常数)时,FISTA算法有二阶的收敛性。
本文介绍了函数的Lipschitz属性与算法收敛性的关系。在前面的算法中,我们要求函数在整个定义域中都是Lipschitz的,因此,我们可以使用固定的步长,例如在算法中使用一个固定的
。在更复杂的情况下,待优化的目标函数
的梯度可能只是局部Lipschitz,即函数
在其定义域中每一个局部是Lipschitz的,那么这个时候,我们就不能固定一个步长,而是需要根据局部的Lipschitz系数,更新每一步的步长值,设计变化步长的优化算法。
作为拓展,之前在《常微分方程与优化算法》中,我们指出数值优化算法可以跟常微分方程联系在一起,即某些数值优化算法在连续的情况可以表示为常微分方程。有趣的是,Lipschitz条件也在常微分方程中有重要的作用。我们在《常微分方程与优化算法》中介绍过,梯度下降算法在连续的情况可以表示为梯度流
常微分方程的存在性定理告诉我们,如果是Lipschitz的,那么微分方程
的解存在且唯一。
上一节主要学习了无约束优化问题的解的条件,这一节主要学习优化问题求解中步长的确定
求解最优化问题的基本方法是迭代算法,迭代算法是指采用逐步逼近的计算方法来逼近精确解,即选择一个初始点 后,根据迭代算法生成
,使得
,其中
为精确解。最优化方法有两种求解方式
首先介绍线搜索方法
这个算法中需要解决三个问题
这一节将先解决问题1和3,第二个问题的解决将留到下一节中介绍
其他说明:线搜索方法和信赖域方法的区别在于是先选择下降的方向还是先选择步长,线搜索方法在 点求得下降方向
在沿
确定步长
,而信赖域方法是先限定步长的范围,再同时确定下降方向
和步长
判断算法的终止条件主要有三种
根据最优解的一阶必要条件,最优解 为平稳定满足
,因此可以使用
作为终止条件
缺点:
即迭代点的改变很小
即目标函数的改善非常小
第二种和第三种终止条件的缺点:无法保证 或
足够小,即无法保证终止时
非常接近
已经确定好了下降方向,现在需要确定步长,使得 最小,记
因为迭代点
和下降方向
已知,因此
是关于
的一元函数
因此线搜索问题转换为求解一元函数最优解的问题,即
表示第
次迭代过程中
的最小点
求解 的方法主要有:
根据最优解的一阶必要条件, 满足
解出等式的解以后需要通过通过Hessen矩阵判断是否为最优解
缺点:
对于精确线性搜索存在的问题,可以采用直接搜索法去求解步长。一般都采用基于搜索区间的直接搜索法,直接搜索法要求事先知道一个包含最优解 的搜索区间
搜索区间的定义:设 是
的极小点,若存在区间
,使得
,并且要求
在此区间是单峰函数。即搜索区间需要满足两个条件
单峰函数的定义:若存在 ,使
在
上单调下降,在
上单调上升,则称
是区间
上的单峰函数,
搜索区间的确定:
采用进退法求初始区间 ,该方法的基本思路是先选定一个初始点
和一个初始步长
,从
起以
为步长向前搜索一步得
。若该点的目标函数值较
处的目标函数值减小了,则加大
继续向前搜索,直到新一点目标函数值较前一点的目标函数值大则停止;否则从
为初始点以
为初始步长向反方向进行搜索
直接搜索法的思想:确定了初始区间 ,如果区间较大求解将非常困难,因此一个思路是不断缩小区间
但仍需保证
在缩小后的区间内,将
缩小到很小的区间时,可以任取区间内的一点
近似于
。因此需要不断的缩小搜索区间,选取两点
,且
常见的直接搜索法:
设 是区间
上的单峰函数,令
令 ,即将初始区间N等分,比较相邻三个点对应的函数值,若对于某个
有
则
,则得到新的搜索区间
。选取新区间以后继续重复上述过程,该算法进行一次搜索区间将缩小为原搜索区间的
令 在搜索区间
中插入两个试探点
,其中
即
若
,则
,产生新的搜索区间
,反之产生的新区间为
。选取新区间以后继续重复上述过程直至
则停止迭代,此时
。该算法进行一次搜索区间将缩小为原区间的
0.618法和均匀搜索法相比
记区间的中点 ,计算该点的导数值
若 ,则
若 ,则
,产生新的搜索区间
若 ,则
,产生新的搜索区间
选取新区间以后重新选取中点继续上述过程,该算法进行一次搜索区间将缩小为原搜索区间的
采用精确搜索法和直接搜索法求解 虽然会使得目标函数在每次迭代中下降较多,但计算量非常大,没必要将线性搜索搞得十分精准,特别在计算的初始阶段,此时迭代点
离目标函数的最优解还很远,过分地追求线性搜索的精度会降低整个方法的效率。可以适当放松对
的要求,只要求满足适当的条件即为
的最优解
4.3.1 Armijo条件
设 ,若
满足
当
时,
,图像是一条直线
当 时,
,图像是在点
的切线
结合图像
4.3.2 Goldsteint条件
称除了满足 Armijo条件以外,还需要满足
其中
满足
结合图像
对一个算法除了要考虑步长及梯度方向的选择以外,还需考虑算法的收敛性,在算法收敛的情况下还需要考虑算法的收敛速度,因为算法的收敛性是判断一个算法优劣的重要标准
若一个算法产生的迭代序列在某种范数
下满足
则称这个算法是收敛的,进一步根据初始点
选取的不同,可以进一步将收敛性分为:
设迭代序列 收敛到
,若存在极限
当
时,称迭代序列
是线性收敛的
当 时,称迭代序列
是超线性收敛的
若存在 ,极限满足
则称迭代序列
是
阶收敛的,一般通常考虑二阶收敛,并且
阶收敛必为超线性收敛
证明:
对极限做一个如下变形
当
,
将非常小,因此
将非常大,若 收敛,则
因此此时是满足超线性收敛的
收敛速度比较:线性收敛 < 超线性收敛 < 阶收敛
对于一个算法,如果它对任意的正定二次型,从任意初始点出发,可以经有限步迭代求得极小值点,则称该算法具有二次终止性

多目标优化是各个领域中普遍存在的问题,每个目标不可能都同时达到最优,并且有现实应用的时效。各个因素必须各有权重。在困局中,平方和方法可用来寻找局部最优解。
作者:Max G. Levy (编译:吴彤)
生命是一连串的优化问题,下班后寻找回家的最快路线;去商店的路上权衡最佳性价比,甚至当睡前“玩手机”的安排,都可以看做优化问题。
优化问题的同义词是找到解决方案,有无数学者想探求在最短时间内,找到最好的解。但最新研究指出,一些二次优化问题,例如变量对可以相互作用的公式,只能“按部就班”找到局部最优解。换句话说“不存在快速计算方法”。
好消息是,另一项研究发现对于三次多项式下的优化问题,存在快速求解的方法。具体而言,可以通过使用平方和检验(sum-of-squares test)找到某些多项式的最低点,进而搜索三次函数的局部最优解。
两项研究时隔两天,出自于同一研究团队:普林斯顿大学的Amir Ali Ahmadi和他的前学生Jeffrey Zhang。


Amir Ali Ahmadi和他的前学生Jeffrey Zhang
Amir Ali Ahmadi是普林斯顿大学运筹学与金融工程系教授,在加入普林斯顿大学之前,曾是IBM Watson研究中心的Goldstine研究员,其对优化理论,动力学和控制的计算以及算法和复杂度有很深的造诣。Jeffrey Zhang是卡内基梅隆大学的客座教授,研究领域包括博弈论、计算复杂性、多项式优化等等。
两篇“涉事”论文分别是:
论文1:On the complexity of finding a local minimizer of a quadratic function over a polytope
贡献:判定二次函数在(无界)多胞形( polyhedron)上是否有局极小值,以及判定四次多项式是否有局部极小值属于NP难。
论文链接:https://arxiv.org/abs/2008.05558
论文2:Complexity aspects of local minima and related notions
贡献:证明了在三次多项式中,某些优化问题容易处理,且给出了寻找三次多项式局部极小值的一个充要条件。
论文链接:https://arxiv.org/abs/2008.06148
这两篇论文,一前一后,证明了复杂性计算研究的现状:某种类型的优化问题很容易解决,而某种类型的问题则必然很难解决。更进一步,他们为从金融到自动系统等各个领域的优化问题确定了新的边界。
1 生活中的优化问题
假设一家汽车厂只生产两种车型,便宜版和豪华版。豪华版的售价高于便宜车,但生产成本更高,生产时间也更长。那么两种车型应该各生产多少?
这个问题可以转化为一个用多项式表达的优化求解问题。
首先,这个问题可以分解为三个元素:

汽车例子仅仅是一个简单的优化问题,变量之间没有相互作用,优化值可以通过求解线性函数得到。但现实中的问题往往非常复杂。
例如,如何选择最佳航空枢纽。枢纽航班波强度和密度的经济性与机场设备设施、机型、航班结构等等有关,只有在这几个方面取得最佳配合的情况下,枢纽中转才能真正发挥作用。
枢纽航空公司在组织航班的时候,希望航班波的强度和密度越大越好,这样就可以提高单位时间内的中转效率,与此带来的单位时间内航班量过大,中转人数过多的高峰处理量,给机场和航空公司带来了巨大的运营压力和成本压力。也就是说,航空公司在枢纽机场的处理能力接近峰值后,会出现快速衰退,导致操作成本快速提高和服务质量急剧下降。
当然,还有很多问题可能比这更复杂。变量之间的三阶交互作用需要用到更复杂的函数。每一步函数复杂性都要为更广泛的问题建模,但是这种复杂性是有代价的,它可能计算不出最优解。
现代优化理论发展于第二次世界大战期间(1939年至1945),当时一位名叫 George Dantzig的科学家设计了一个寻找线性优化问题解的程序,被应用到美国国防部采购飞机和海外运送物资的战时实践上。
在接下来的几十年里,研究人员跟随George的领导,开发了更快的算法,为日益复杂的现实问题找到最佳解决方案。
但在20世纪80年代,这些进步遇到了一个不可逾越的障碍。研究人员发现,解决优化问题的快速算法不可能存在。他们认为,这些问题从根本上来说太复杂了。
如果无法获得最优解决方案,还能怎么办? 近似解,或者“局部”最优解。
局部最优解可能并不代表最佳结果,但它们比任何类似解都要好。它们是做出决策的“足够好”的方式,比如每辆车要生产多少辆,不能通过对某些变量的微小调整来改进,只有大规模的重组才能导致绝对最好的结果,但对于大问题,这种计算过于密集。
鉴于这一切,自20世纪90年代初以来,研究人员一直试图确定:是否存在一种快速找到局部最优解的方法。
当研究人员想要确定一个问题在计算上是否难以解决时,他们通常会将其等同于一些已知复杂性的问题。比如如果知道A问题很难解决,可以证明,解决问题B将为解决A提供一种方法。
在Amir Ali Ahmadi和Jeffrey Zhang的第一篇论文中,他们将二次优化的挑战与所谓的最大稳定集问题进行了匹配。当然,最大稳定集问题是一个著名的并且可证明的难题。
“稳定集”(stable set)是指图表中两个节点没有直接相连的任何节点列表。最大稳定集问题要即找到图表中最大规模的稳定集。即使你只想知道是否存在一个给定大小的稳定集,但要确定这个答案,计算相当复杂。
去年6月,Ahmadi和Zhang将最大稳定集问题重新定义为搜索局部最优解的特殊情况。他们提出了一种将稳定集问题表示为二次优化问题的方法。于是,寻找一个具有一定规模的稳定集就变成了寻找这个优化问题的局部最优解的问题。
但是他们知道,依然没有一种很快速的计算方法来找到这些稳定集,这意味着,对于二次函数优化问题,局部最优解和真正最优解一样难以找到。
“直觉上,局部最优解应该更容易,但出乎意料的是,他们二人证明两种解都很难。”荷兰国家数学和计算机科学研究所(CWI)的Monique Laurent说。
Ahmadi和Zhang排除了总能找到某些二次优化问题局部最优解的有效算法的存在。与此同时,他们想知道:在不包含约束条件的简化条件下能够解决三次优化问题么?
三次多项式在许多实际方法中都很重要。它们为思考变量之间的三阶相互作用提供了一个数学框架。增加一种关系使得关系的清晰度提高,从而极大地改善机器学习性能,比如在文本挖掘中,大家希望算法能从大数据集中提取意义。
例如,你向计算机输入一段文本,并要求它确定这段文本的内容。计算机注意到“苹果”这个词经常出现,但是没有更多的信息,导致“苹果”这个词语仍有歧义。
可能是水果,也可能是公司,或者其他。
但如果“苹果”和“橘子”同时出现,计算机会更加确定这是水果。但还是有可能出错,因为橘子也可能是一家公司。所以这时候引入第三个词语,如“瓜”,即引入了立体关系,可能会更加确信文本谈论的是农产品。
但是,清晰度的增加也带来了复杂性。
从2019年初,Zhang就开始探索解决这个问题的不同方法,但被卡住了,直到Ahmadi建议他尝试一种叫做平方和的技术,Ahmadi以前曾用这种技术解决其他优化问题。
“平方和”指的是一些多项式可以表示为其他多项式的平方和。
例如: 平方和揭示了最初输入的多项式的属性。因为实数的平方不可能为负,所以如果将一个多项式表示为平方和,证明它总是输出一个非负值。这是一种快速的检验方法。然而,这种方法在有约束的二次优化问题中不起作用,这就是为什么Ahmadi和Zhang不能在他们的二次方程中利用它。
但是对于没有约束的三次优化问题,平方和成为寻找局部最优最小解时的重要方法。如果将多项式函数的图形描绘成一条浮动在横轴上方的曲线,它的最低点是对应于变量的特定排列。
这种算法可以快速循环遍历一系列输入,反复测试多项式是否为平方和。此时,算法会将曲线向下拖动,无限趋近于横轴。此时,另一种算法可以快速表明低点的坐标。
此时,Zhang和Ahmadi才将优化问题向前推进了一小步,他们的突破在于发现可以通过平方和检验找到某些多项式的最低点,从而寻找三次函数的局部最优解。
在像 这样的三次多项式的图中,一端总是指向负无穷。所以三次方程不可能处处为正,可以用平方和检验。但是Ahmadi和Zhang想出了一种方法,只关注曲线向上的那部分。
Zhang说:“对于三次函数求解的问题,我们总是可以把函数拖到我们想要的位置,解决了三次函数局部最优解的重要理论问题。”
现在,Ahmadi和Zhang正在尝试将这一方法升级为一种更普适的算法来提高实用价值,不仅可以处理二次函数,还有三次函数。这将使程序更加稳定,并提高机器学习任务的性能。
目前,优化问题求解的难点不仅在于目标数比较多的多目标优化,甚至大规模多目标优化,动态多目标优化,偏好众目标优化,还有计算求解的时效问题,工具的普适问题。在处理实际情况下的优化问题中,进一寸有一寸的欢喜。
编译来源:
https://www.quantamagazine.org/surprising-limits-discovered-in-quest-for-optimal-solutions-20211101/
欢迎关注(公众号) @运筹OR帷幄 ,了解更多运筹学、人工智能及相关学科的干货资讯。
知乎专栏:
『运筹OR帷幄』大数据时代的运筹学
『运筹AI帷幄』大数据时代的人工智能
获得最新运筹学及其相关学科的干货资料、行业前沿信息、学术动态、硕博offer信息等。特别适合你~
欢迎大家交流。
也欢迎大佬们投稿和商业合作,学术信息、会议通讯、征稿启事、硕博招生信息等免费推广。
当优化问题具有可微的目标函数和约束函数时:
一个解满足KKT条件时,一定为全局或局部最优解吗?
如果这个解还满足Slater条件呢?
这些条件是最优解的充分条件还是必要条件呢?
当Slater条件成立时,KKT条件是最优性的充要条件,此时对偶间隙为零(强对偶性成立)。[1]
如果Slater条件不成立,满足KKT条件的解也是最优解。[1]
如果Slater条件不成立,即使优化问题存在全局最优解,也可能不存在解满足KKT条件。例如:
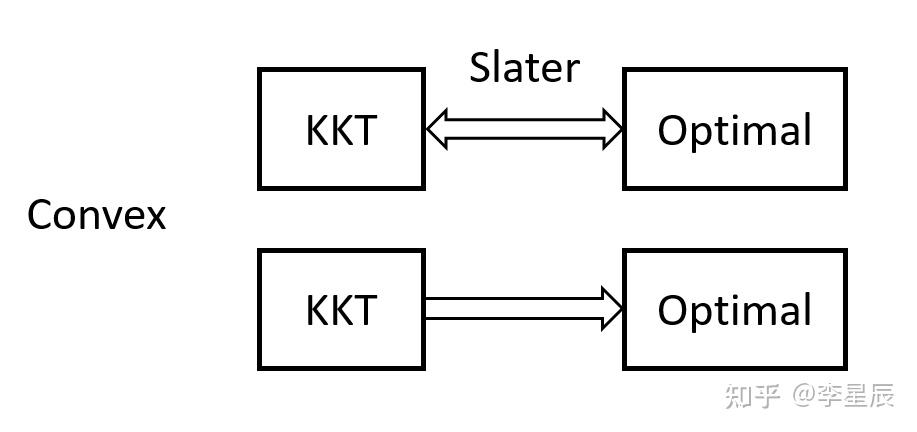
局部最优解满足Slater条件,则满足KKT条件,此时KKT条件是局部最优解的必要条件。[2]
局部最优解不满足Slater条件,则满足FJ条件,未必满足KKT条件。[2]
满足KKT条件的解未必是局部最优解(如鞍点)。

在回归(拟合)问题中,基于不同的概率假设,会导出不同的回归模型,这些回归模型又会变成不同的优化问题,从简单到复杂可以写出下面这三类:
P1-最小二乘法:
P2-更一般的范数:
P3-或者更一般的问题:
其中是个偶函数,正半轴单调增加的函数。在线性回归特别是鲁棒回归的M-estimator,这些问题都可能遇到,第一个一般的最小二乘法求解方法就不说了,直接可以用正规方程就能得到显式表达式:
P1是正常的最小二乘回归,P1是P2的特例。在P2中,p=1时就是LAD,典型的鲁棒线性回归方法了。P2是P3的特例,P3中还可以取 为Huber loss/Bisquare/等等各种M-estimator
对于鲁棒回归,重点自然是P2和P3,那么接下来介绍一个迭代法求解这两个更一般的问题,也就是所谓的迭代重加权最小二乘法(Iterative Reweight Least Square, IRLS)。在派大西读本科的时候这个算法还挺火的,大概是由于压缩感知的原因,当时大家对第二个模型的特别感兴趣,所以当时各种算法变形分析之类的paper特别多。当然算起来再早个几十年IRLS已经被发明了。
作为一种迭代算法,假设是当前的迭代解,作为对问题P2的局部近似,求解:
变成了一般加权最小二乘问题,其迭代有显式表达式:
其中,为
拼出来的对角矩阵。
然后再看看P3,P3相对P2是更一般的问题。一个比较正常的思想的话:在处用二次函数替换掉当前的
,怎么替呢,比如Newton-Raphson方法,看着有点复杂,总归也是变成最小二乘问题了
但迭代重加权最小二乘更简单一点,注意到P3的一阶最优化条件为
上面的等式再变一下形:
因此可以构造迭代算法:
等价于求解极小化问题
继续用显式表达式
为
拼出来的对角矩阵。其中,由于假设了
是偶函数而且在正半轴上单调增,那么,因此不用担心权重的正负问题,总是正的就是了。
然后对比一下两者的效果,P2中选取p=2,1两种,也就是Ordinary Least Square (OLS)
与Least Absolute Deviations (LAD)
构造下数据集,用两种模型:
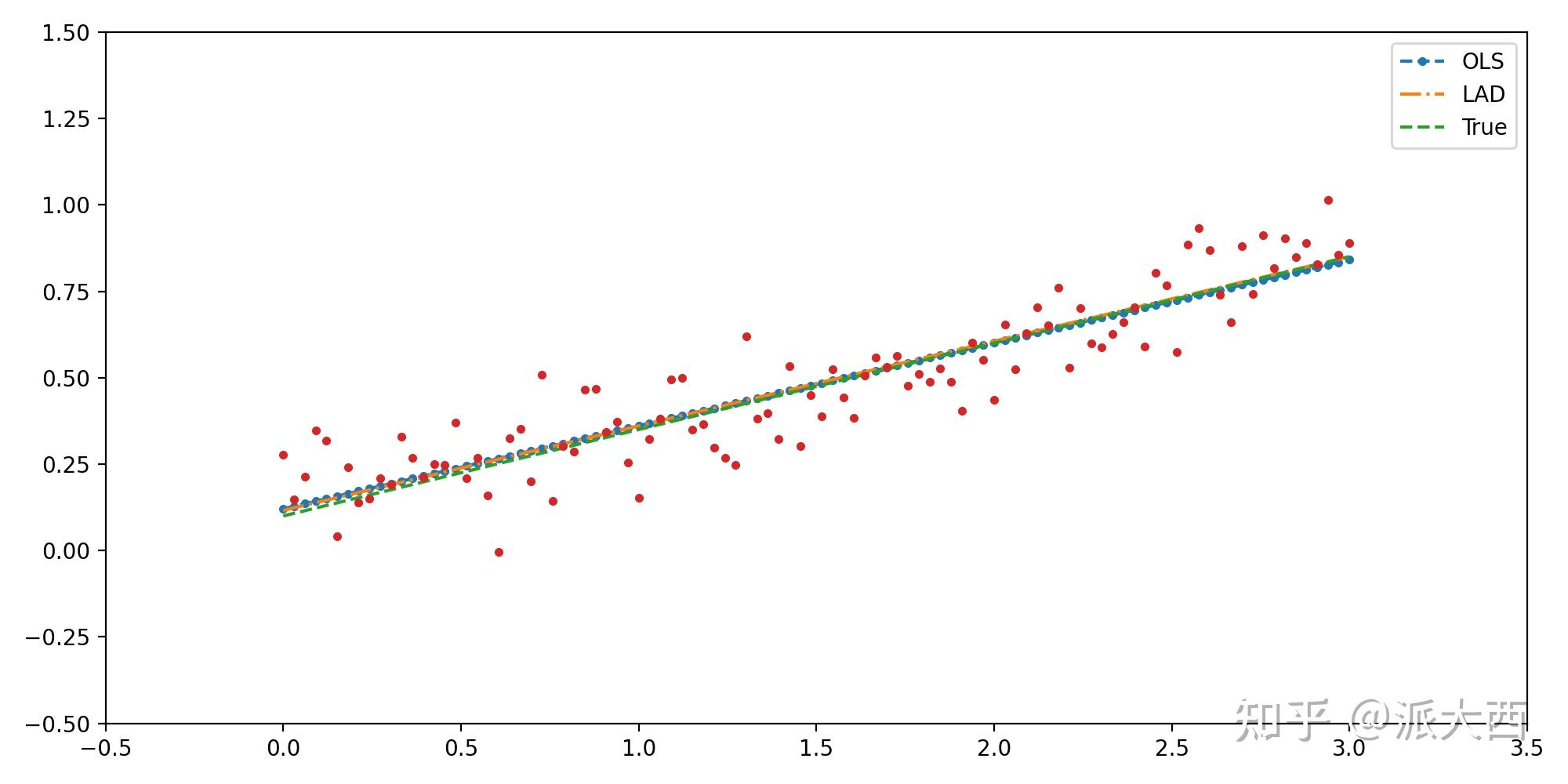
没啥区别,然后加上离群值,再用IRLS求解看看两种模型的效果:
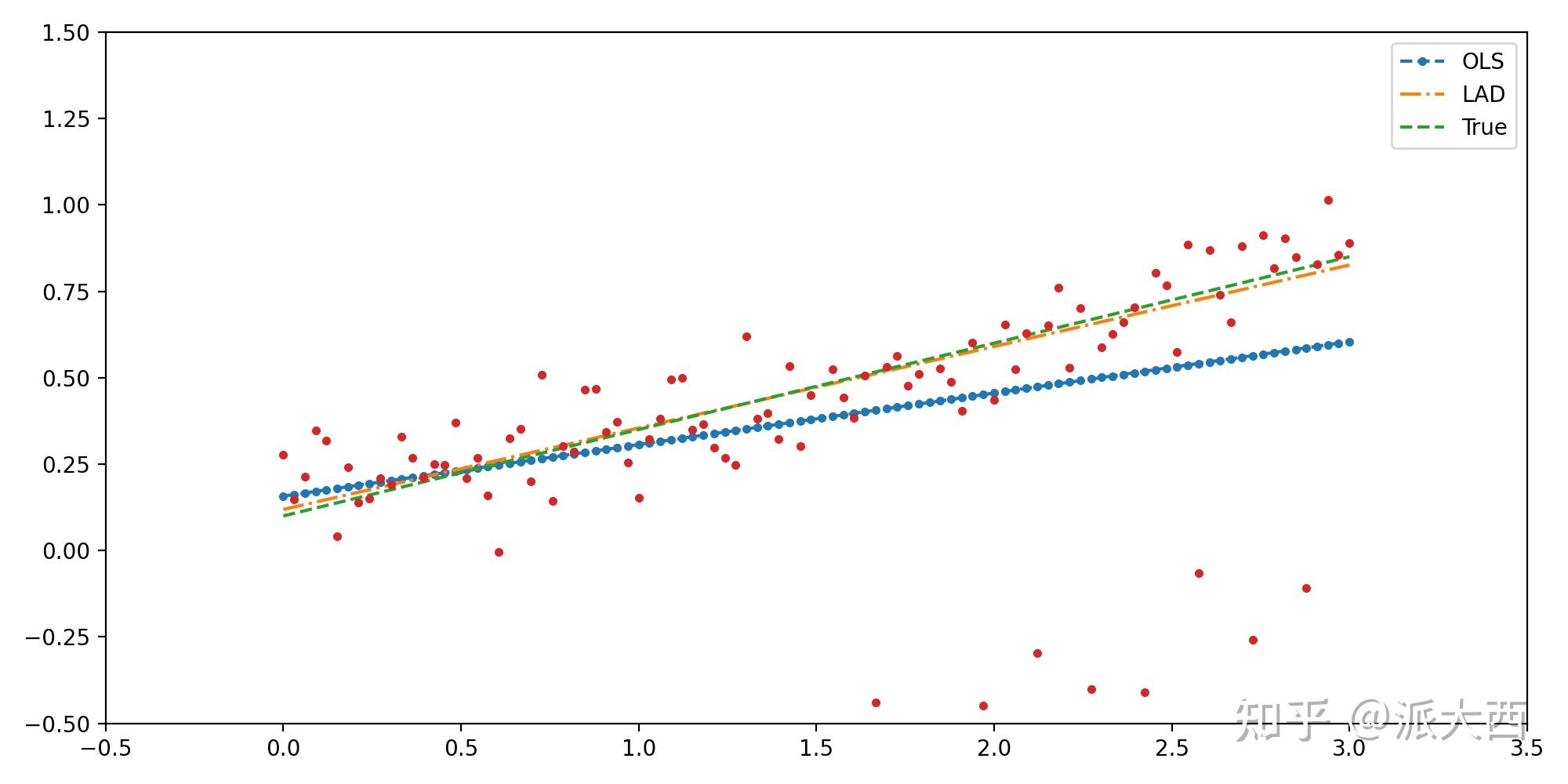
正如大家所料,OLS受到了异常点的较大干扰,对LAD影响就小很多,这就是所谓的“鲁棒回归”
那么今天学习了迭代重加权极小二乘算法,并且用来求解鲁棒回归问题,那么就到这儿吧@派大西
我们考虑以下有监督机器学习问题。假设输入数据 依据输入空间
的真实分布
独立同分布地随机生成。我们想根据输入数据学得参数为
的模型
,该模型能够根据输入
给出接近真实输出
的预测结果
。我们下面将参数
对应的模型简称为模型
,模型预测好坏用损失函数
衡量。则正则化经验风险最小化(R-ERM)问题的目标函数可以表述如下:
其中 为模型
的正则项。
由于在优化算法的运行过程中,训练数据已经生成并且保持固定,为了方便讨论且在不影响严格性的条件下,我们将上述目标函数关于训练数据的符号进行简化如下:
其中 是模型
在第
个训练样本
上的正则损失函数。 不同的优化算法采用不同的方法对上述目标函数进行优化,以寻找最优预测模型。看似殊途同归,但实践中的性能和效果可能有很大差别,其中最重要的两个特性就是收敛速率和复杂度。
假设优化算法所产生的模型参数迭代序列为 ,其中
为第
步迭代中输出的模型参数,R-ERM问题的最优模型为
。一个有效的优化算法会使序列
收敛于
。我们用
与
在参数空间中的距离来衡量其接近程度,即
若用正则化经验风险的差值来衡量,则为
来衡量。
可视为关于
的函数,收敛的算法都满足随着
,有
,不过其渐进收敛速率各有不同。通常用
的衰减速率来定义优化算法的渐进收敛速率。
收敛速率各阶数对比可参照下图:

优化算法的复杂度需要考虑单位计算复杂度与迭代次数复杂度。单位计算复杂度是优化算法进行单次迭代计算需要的浮点运算次数,如给定 个
维样本,采用梯度下降法来求解模型的单位计算复杂度为
,随机梯度下降法则是
。迭代次数复杂度则是指计算出给定精度
的解所需要的迭代次数。比如若我们的迭代算法第
步输出的模型
与最优模型
满足关系
,若要计算算法达到精度 所需的迭代次数,只需令
得到
,因此该优化算法对应的迭代次数复杂度为
。注意,渐进收敛速率更多的是考虑了迭代次数充分大的情形,而迭代次数复杂度则给出了算法迭代有限步之后产生的解与最优解之间的定量关系,因此近年来受到人们广泛关注。
我们可以根据单位计算复杂度和迭代次数复杂度来得到总计算复杂度,如梯度下降法单位计算复杂度为 ,在光滑强凸条件下的迭代次数复杂度为
,则总计算复杂度为
。随机梯度下降法单位计算复杂度为
,在光滑强凸条件下的迭代次数复杂度为
,则总计算复杂度为
。
目前大多数优化算法的收敛性质都需要依赖目标函数具有某些良好的数学属性,如凸性和光滑性。近年来由于深度学习的成功人们也开始关注非凸优化问题。我们这里先讨论凸优化的假设。
凸函数 考虑实值函数 ,如果对任意自变量
都有下列不等式成立:
则称函数 是凸的(可以直观理解为自变量任何取值处的切线都在函数曲面下方)。
凸性会给优化带来很大方便。原因是凸函数任何一个局部极小点都是全局最优解。对于凸函数还可以进一步区分凸性的强度,强凸性质的定义如下:
强凸函数 考虑实值函数 和
上范数
,如果对任意自变量
都有下列不等式成立:
则称函数 关于范数
是
-强凸的。 可以验证当函数
是
强凸的当前仅当
是凸的。
下图中给出了凸函数、强凸函数和非凸函数的直观形象:

光滑性刻画了函数变化的缓急程度。直观上,如果自变量的微小变化只会引起函数值的微小变化,我们说这个函数是光滑的。对于可导和不可导函数,这个直观性质有不同的数学定义。
对于不可导函数,通常用Lipschitz性质来描述光滑性。
Lipschitz连续 考虑实值函数 和
上范数
,如果存在常数
都有下列不等式成立:
则称函数 关于范数
是
-Lipschitz连续的。
对于可导函数,光滑性质依赖函数的导数,定义如下:
光滑函数 考虑实值函数 和
上范数
,如果存在常数
都有下列不等式成立:
则称函数 关于范数
是
-光滑的。 下图是Lipshitz连续函数和光滑函数的直观形象:
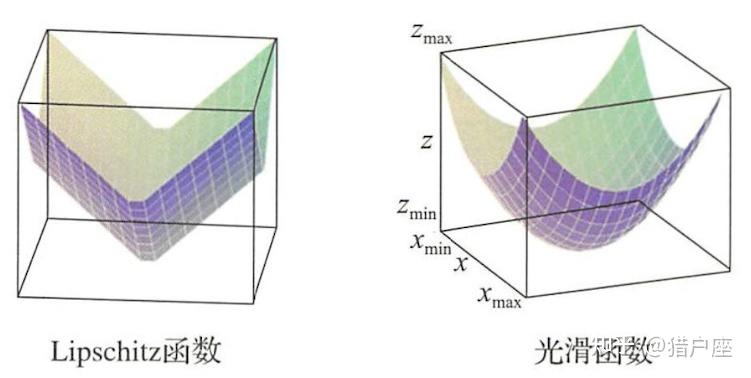
可以验证,凸函数 是
-光滑的充分必要条件是其导数
是
-Lipschitz连续的。所以,
-光滑函数的光滑性质比Lipschitz连续的函数的光滑性质更好。
数值优化算法的发展历史如下图所示:
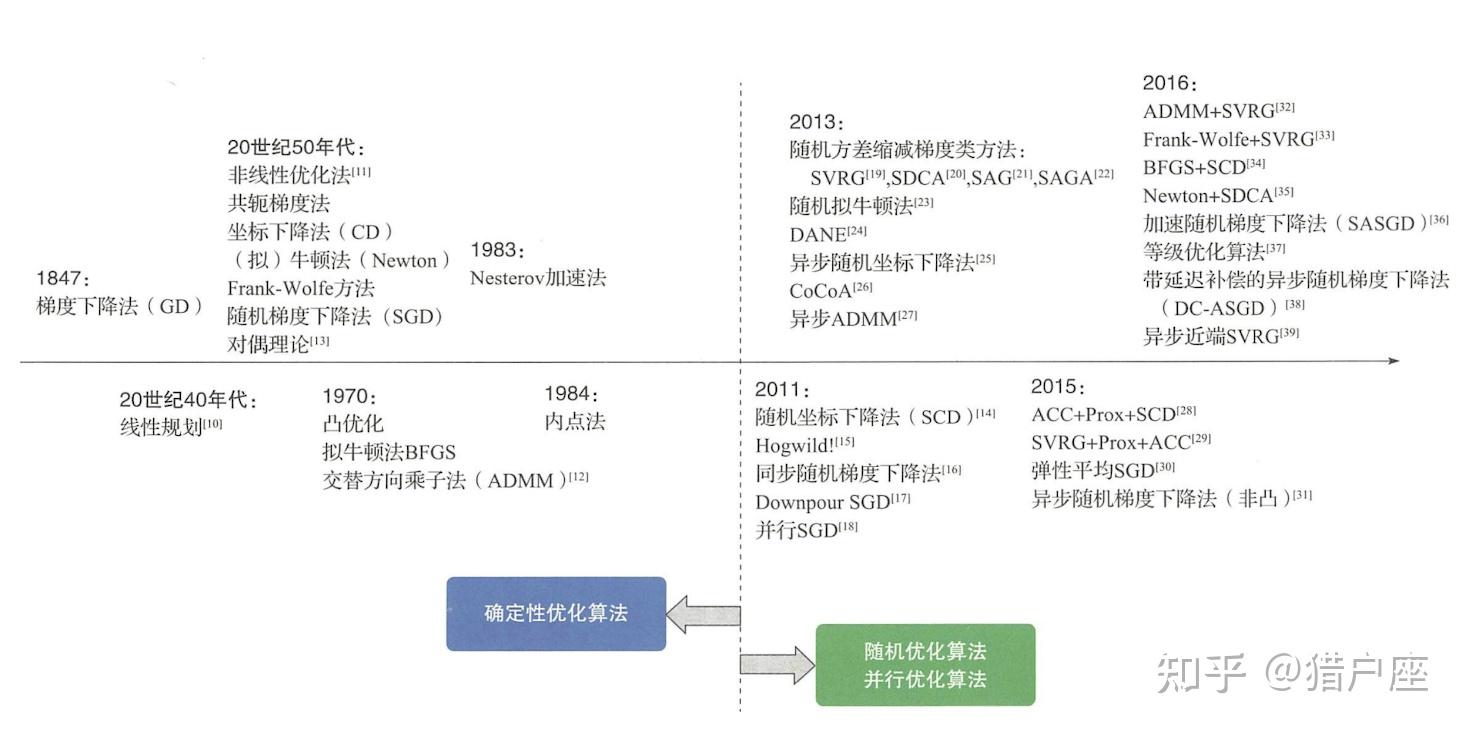
可以看到,优化算法最初都是确定性的,也就是说只要初始值给定,这些算法的优化结果就是确定性的。不过近年来随着机器学习中数据规模的不断增大,优化问题复杂度不断增高,原来越多的优化算法发展出了随机版本和并行化版本。
为了更好地对众多算法进行分析,我们对其进行了如下分类:
以上分类可以用下图加以总结:
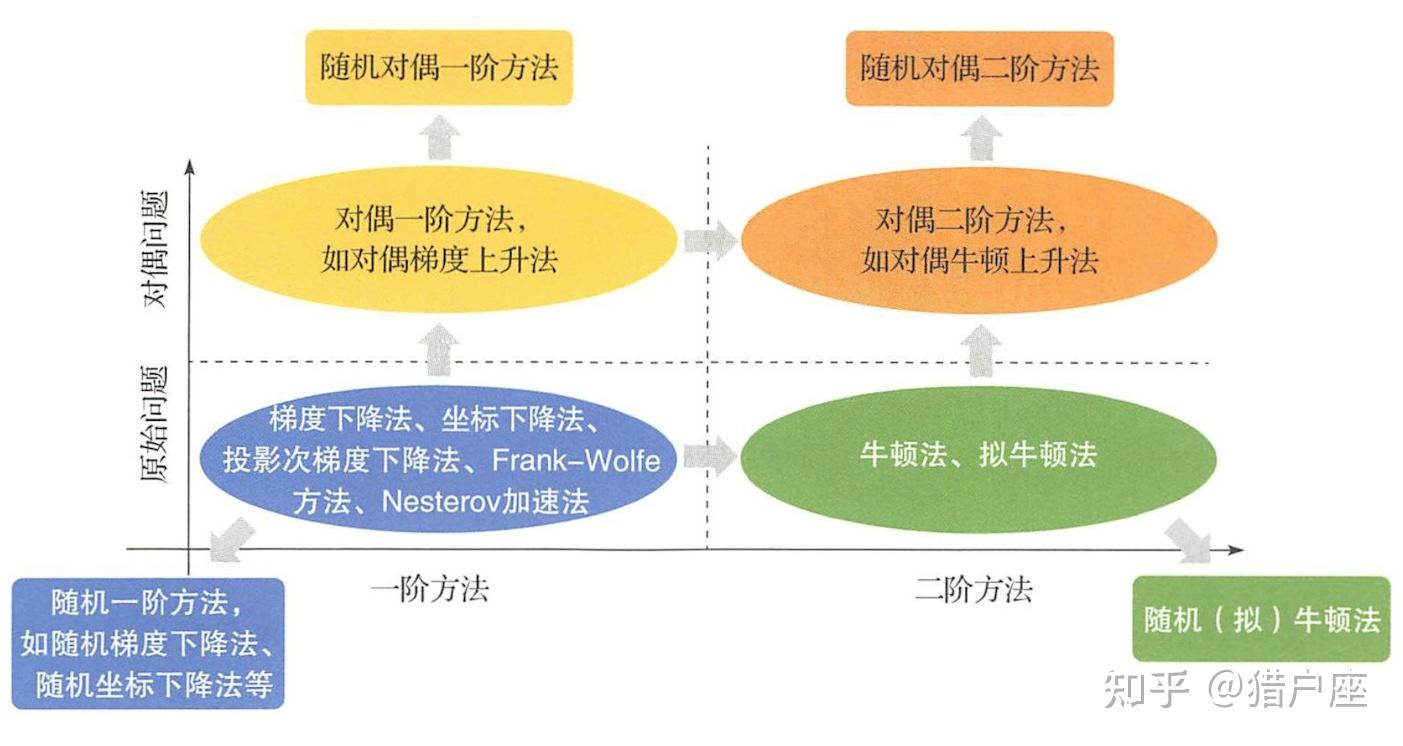
我们下面的博客将依次讨论一阶和二阶确定性算法、单机随机优化算法和并行优化算法,大家可以继续关注。
我们在上一篇文章《数值优化:算法分类及收敛性分析基础》介绍了数值优化算法的历史发展、分类及其收敛性/复杂度分析基础。本篇博客我们重点关注一阶确定性优化算法及其收敛性分析。
梯度下降法[1]是最古老的一阶方法,由Cauchy在1847年提出。 梯度下降法的基本思想是:最小化目标函数在当前迭代点处的一阶泰勒展开,从而近似地优化目标函数本身。具体地,对函数 ,将其在第
轮迭代点
处求解下述问题:
上式右端关于自变量 是线性的,并且使得
最小的方向与梯度
的方向相反。于是梯度下降法的更新规则如下:
其中 。
梯度下降法描述如下:

针对不同性质的目标函数,梯度下降法具有不同的收敛速率。由于梯度下降法只适用于梯度存在的函数(没有梯度需要考虑使用次梯度的方法),这里考虑梯度下降法对于光滑凸函数和光滑强凸函数的收敛速率。
光滑凸函数收敛性 假设目标函数 是凸函数,且
-光滑,当步长
时,梯度下降法具有
的次线性收敛速率:
光滑强凸函数收敛性 假设目标函数 是
-强凸函数,且
-光滑,当步长
时,梯度下降法具有
的线性收敛速率:
其中 ,一般被称为条件数。
通过以上两个定理可知,强凸性质会大大提高梯度下降法的收敛速率。进一步地,强凸性质越好(即 越大),条件数
越小,收敛越快。
而光滑性质在凸和强凸两种情形下都会加快梯度下降法的收敛速率,即 越小(强凸情景下,条件数
越小),收敛越快。可以说凸情形中的光滑系数和强凸情形中的条件数在一定程度上刻画了优化问题的难易程度。
梯度下降法有两个局限,一是只适用于无约束优化问题,二是只适用于梯度存在的目标函数。投影次梯度法[2]可以解决梯度下降法的这两个局限性。
投影次梯度下降法相比梯度下降法,具有次梯度选择和约束域投影两个特性:
得到 。

寻找投影的过程可以经由投影映射 来完成:
投影次梯度下降法描述如下:

在一定步长的选取规则下,投影次梯度法是收敛的,并且收敛速度也依赖于目标函数的凸性和光滑性。
对于 -光滑的凸/强凸函数,当步长为
时,投影次梯度下降法的收敛率和梯度下降法相同,对于凸函数是
,强凸函数是
。
不过,由于投影次梯度算法适用于有次梯度存在的目标函数,因而不仅适用于光滑函数的优化,也适用于Lipschitz连续函数的优化。对于Lipschitz连续函数,投影次梯度下降法收敛。对于凸函数,步长 时,收敛速率为
;对于强凸函数,步长
时,收敛速率为
。可以看到其收敛速率在凸和强凸两种情形相比光滑函数显著降低,都是次线性。
近端梯度法[3]是投影次梯度法的一种推广,适用于如下形式的部分不可微的凸目标函数的优化问题:
其中 是其中的可微凸函数部分,
是不可微的凸函数(例如
正则项)。算法的基本思想是先按照可微的
函数进行一步梯度下降更新:
然后再经过近端映射 做为本轮最终的迭代更新:
近端梯度下降法描述如下:

如下定理所示,近端梯度下降法可以达到线性收敛速率。
近端梯度下降法收敛性 假设目标函数中的 函数是
上的
-强凸函数,且
-光滑;
函数是
上的凸函数, 当步长
时,近端梯度下降法具有
的线性收敛速率:
其中 为
函数的条件数。
Frank-Wolfe算法[4]是投影次梯度下降法的另一个替代算法。投影次梯度算法虽然适用于有约束优化问题,但是如果投影的计算很复杂,投影次梯度下降的效率将会称为瓶颈。为了解决此问题,不同于投影次梯度下降法中先进行梯度下降再对约束域进行投影的做法,Frank-Wolfe算法在最小化目标函数的泰勒展开时就将约束条件考虑进去,直接得到满足约束的近似最小点,即:
为了使算法的解更稳定,Frank-Wolfe算法将求解上述子问题得到的 与当前状态
做线性加权:
如下图所示:
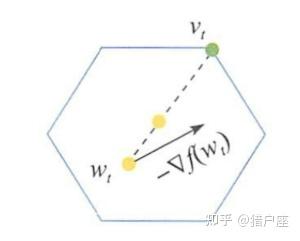
Frank-Wolfe算法描述如下:

Frank-Wolfe算法收敛速率如下列定理所示:
Frank-Wolfe法收敛性 假设目标函数中的 函数是
上的凸函数,且
-光滑,当加权系数
时,Frank-Wolfe算法具有
的次线性收敛速率:
其中 。 由于Frank-Wolfe算法的收敛速率和投影次梯度下降法相同,可以依据要解决问题中的投影计算是否困难,在两种算法中选择一种使用。
考虑以上所有的一阶算法。在Lipschitz连续的条件下,梯度下降法达到了一阶算法的收敛速率下界。然而对于光滑函数,一阶方法的收敛速率的下界小于梯度下降法的收敛速率。一阶方法在凸情形下的收敛率下界为 ,强凸情形下的下界为
;而梯度下降法在凸情形下的收敛率为
,强凸情形下的收敛率为
。这说明我们可以针对光滑函数设计收敛速率更快的一阶方法。
Nesterov在1983年对光滑度目标函数提出了加快一阶优化算法收敛的方法[5]。我们这里以梯度下降法为例,介绍Nesterov加速法的具体实现。 Nesterov算法的基本原理如下图所示:
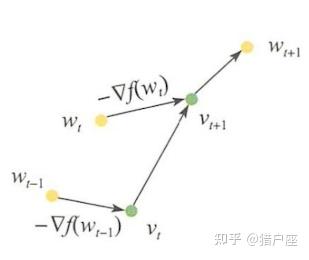
当任意时刻 ,对当前状态
进行一步梯度迭代得到辅助变量
:
然后将新的辅助变量和上一轮迭代计算的辅助变量 做线性加权,做为第
轮迭代的参数
。对于凸和强凸的目标函数,线性加权系数有所不同。
具体地,对于强凸的目标函数,加权规则如下:
其中 ,
为条件数。
对于凸的目标函数,加权规则如下:
其中 ,
,
。
Nesterov加速算法描述如下:

Nesterov证明了用以上方法加速之后的梯度下降法的收敛速率可以达到针对光滑目标函数的一阶方法的收敛速率下界:
光滑凸函数收敛性 假设目标函数 是凸函数,并且
-光滑,当步长
时,Nesterov加速法能够将收敛速率提高到
(不过仍是次线性收敛速率):
光滑强凸函数收敛性 假设目标函数 是
-强凸函数,并且
-光滑,当步长
时,Nesterov加速法能够将收敛速率提高到
(不过仍是线性收敛速率):
其中 为条件数。
坐标下降法[6]是另外一种常见的最小化实值函数的方法。其基本思想是,在迭代的每一步,算法选择一个维度,并更新这一维度,其它维度的参数保持不变;或者将维度分为多个块,每次只更新某块中的维度,其它维度保持不变。坐标下降法的更新公式如下:
其中, 为第
个维度块的约束域。
对于维度的选择,坐标下降法一般遵循以下本征循环选择规则(Essential Cyclic Rule):存在一个常数 ,使得对任意的
,对于每一个维度
,在第
轮和第
轮之间都至少选择一次。最常见的方法是循环选择规则,即对于任意
,分别在第
次算法迭代中选择维度
(即每隔
轮选择一次)。
坐标下降法的算法描述如下所示:

可以证明对于强凸并且光滑的目标函数,循环坐标下降法具有线性的收敛速率[6]。
本文是关于汪哲培博士在深蓝学院讲授的公开课程《机器人学中的数值优化》课程内容的总结和梳理,便于日后回顾。具体内容非常精彩,大家可到深蓝学院进行学习。
约束优化问题的一般形式如下:
其中,
,
代表不等式约束,
代表等式约束,下标代表约束的个数。
在众多类型的约束优化问题中,有几类问题目前得到了较为广泛的研究,取得了不错的结果。其中包括了:线性规划(Linear Programming,LP),二次规划(Quadratic Programming,QP),二阶锥规划(Second-Order Conic Programming,SOCP),半定规划(Semi-Definite Programming,SDP)。
线性规划的一般形式:
二次规划的一般形式:
二阶锥规划的一般形式:
半定规划的一般形式:
一般来说,上述四类优化问题存在如下关系:线性规划
二次规划
二阶锥规划
半定规划。
解决一般的线性规划问题的通用算法很多,例如:单纯形法、内点法等等。然而,在机器人领域,常常会面临一些优化变量维度很低,但是约束数量很多的优化问题。针对这类优化问题找到高效的求解方法对于机器人应用来说非常重要。
举个例子,给定一个凸多面体 ,想要在凸多面体的内部找到一个点,使得它距离凸多面体各个平面的安全距离最大?这个问题可以建模为,定义优化变量为
,然后求解优化问题:
。这个优化问题中,优化变量的维度是
,通常三维环境中这个维度就是4,然而,
的取值可能非常大,也就是凸多面体的面数很多,约束数量很大。
针对这类问题,课程中提出了一类Seidel's算法进行求解。这个算法的核心思想是分成两个步骤:(1)逐个加入线性约束,判断当前的最优解是否满足新加入的线性约束,满足的话则继续添加下一个约束,不满足的话就去计算基于当前已加入的约束条件下,新的最优解。(2)计算新的最优解的方式是:把所有已加入的约束投影到新加入的约束超平面上(因为最优解一定在新加入约束超平面内),这样优化问题的维数会降低1维,然后求解这个降维后的问题即可。总的来说,Seidel's方法基于两个思想,一个是逐步添加约束,另一个是利用递归思想把高维优化问题降维求解。具体的计算方法可Google搜索:Seidel’s LP algorithm。
Seidel’s算法通常的时间复杂度为 ,其中,
是优化变量的维数,
是约束的个数,当
取值较小时,可以认为Seidel’s的时间复杂度就是
,也就是和约束的个数成线性复杂度。因此,采用Seidel’s算法求解低维多约束的线性规划问题是非常高效的。
通用的求解二次规划问题的算法和求解器也非常多。然而,对于机器人领域中常见的低维多约束问题,本课程中也介绍了一种Seidel's算法的二次规划推广版本。这个算法的时间复杂度也是 ,其中,
是优化变量的维数,
是约束的个数。这个算法应该是汪博自己推广得到的,没有找到对应的文章,具体的计算方法可以参考本课程讲义。
前面阐述的是一些约束优化问题的特例,比如低维多约束的线性规划、二次规划问题。对于一般的约束优化问题,有一些将其转换为无约束优化问题的方法。接着,我们可以采用第一部分介绍的无约束优化算法进行求解。
罚函数法的核心思想是把违反约束的程度转换为一种惩罚值,加入到目标函数中,当违反约束程度越大时,目标函数值就会越大,因此倾向于选取约束范围内的解。允许当前解违背约束,这是罚函数法的一个特点。
考虑带有等式约束的优化问题:
通过罚函数方法,将原问题转换为无约束优化问题:
随着 不断增大,直至增大到正无穷,无约束优化问题的最优解会和原问题的最优解越来越接近。
考虑带有不等式约束的优化问题:
通过罚函数方法,将原问题转换为无约束优化问题:
障碍物函数法主要针对不等式约束。主要思想是设置一道高墙,避免迭代过程中,迭代解跑出约束范围。因此,在障碍函数法中是不允许当前解违背约束的,这与罚函数法有显著的区别。
考虑带有不等式约束的优化问题:
通过障碍函数方法,将原问题转换为无约束优化问题:
(1)logarithmic barrier (2)inverse barrier
(3)exponential barrier
当 越来越接近0的时候,障碍函数趋近于无穷大,此时无约束优化问题的最优解和原问题的最优解基本完全一致。
考虑一个具有等式约束的凸优化问题,形式如下: 定义其Lagrange函数为:
基于Lagrange函数的定义,原始问题可以转换为如下问题: 。可以对这个新的优化问题进行分析,当
时,
,和
无关,因此
。当
时,
,因为
可以任意取到正负无穷,由于我们要minimize这个Lagrange函数,所以不可能让
这种情况出现。
如何求解这个问题呢?这里介绍的是 Uzawa's method.
一般来说,对于 的优化问题,
得到的最优解
不是一个关于
的连续函数(显然,当
和
时取值是完全不同的),这会导致在优化:
的时候是非常困难的。
然而,当 相对于
是严格凸函数的时候, 把minimize和maximum调换顺序后的优化问题,即
这个问题会变得更加好求。因为,
得到的最优解
是一个连续函数。
此外,冯诺依曼提出了一个定理,也就是: 。并且,当
是连续凸函数时,等号成立。
因此,我们可以通过求解 问题来求解原问题的最优解。
具体方法为:
首先,优化 问题,即求解
然后,优化 , 利用梯度下降(上升)法, 更新Lagrange乘子,
最后,随着迭代的进行,不断重复 和
的更新,直至达到全局最优解。
相比于前面介绍的罚函数法、障碍函数法、拉格朗日松弛方法,增广拉格朗日方法是一种更加成熟可靠的方法。罚函数法、障碍函数法随着 的变化,最终的最优解附近的Hessian矩阵条件数会越来越大,性质越来越恶劣。拉格朗日松弛方法对目标函数有严格凸的假设,并且只考虑等式约束的情况。然而,增广拉格朗日方法是一种相对可靠的方法,能够应用于绝大多数的约束优化问题。
考虑一个具有等式约束的优化问题,形式如下:
定义其Lagrange函数为: 。根据前文的介绍,原始问题可以转换为如下问题:
。然而,对于
这个优化问题,当
时,
会取到无穷大,当
,
会取任意值。显然,这样得到的
函数是一个不连续的函数,外层优化极难进行。
算法原理:
在增广拉格朗日方法里,把原始问题进行了一定改造,加入了一个正则项,也就是对 的取值进行约束,让
围绕一个
进行变化,从而使得原问题变得连续。改造后的Lagrange函数如下:
其中,
是一个预先定义的先验值,
是一个参数。
当然,这样的改造存在一个问题:由于改造过后的问题相比于原问题多了一项: ,如何保证改造过后的优化问题和改造前的最优解一致呢?一般来说,有两种手段:
问题求解:
上述问题可以进行分步求解,首先求解内层的优化问题:
内层优化问题的最优解是:
把 最优解带入原始问题,得到如下优化问题:
上述优化问题是一个无约束优化问题,可以用之前介绍的无约束优化方法轻松求解,例如BFGS、牛顿法、梯度下降法等等。
总结一下,对于等式约束的增强拉格朗日方法的迭代求解过程: 其中,
代表的是
的放大系数,
代表的是
的上限。注意到,上面的
函数的形式和上推导的行驶略有不同,主要在于多了一项
,这一项对于
的优化没有影响,所以可以对结果无影响。
为什么叫增广拉格朗日方法:
换一个视角, 可以看成是下面问题的Lagrange函数,即:
这里面,当
满足约束时,上述问题和原问题是完全等价的,其中
就是所谓的增广项,这也是这个方法被称为增广拉格朗日算法的原因!!!
考虑一个具有不等式约束的优化问题,形式如下:
通过引入松弛变量,把不等式约束转换为等式约束: 于是,采用等式约束的增强拉格朗日方法,上述问题等价于:
进一步针对上述优化问题进行讨论,当
时,要使得目标函数最小,
应该取0。当
时,要使得目标函数最小,
。所以,最优的
取值如下:
所以,把最优的 取值带入,优化问题转换为了:
同时,最优的
取值带入Lagrange乘子的更新过程,可得:
对于含有等式约束和不等式约束的优化问题: 总结一下,对于含有等式约束和不等式约束的增强拉格朗日方法的迭代求解过程:
其中,
代表的是
的放大系数,
代表的是
的上限。
 QQ:88888888
QQ:88888888 13899999999
13899999999

 返回顶部
返回顶部
